Organizations today face dual challenges in managing data. They need to extract maximum business value from information. But also protect sensitive customer data and meet expanding regulations. Data masking balances these competing needs.
In this guide, we’ll explore how masking helps boost efficiency through seamless data sharing. We’ll also look at how it strengthens compliance with privacy rules. Let’s dive in.
The Dilemma of Sharing Sensitive Data
On one hand, technology teams need broad data access to:
- Develop and test applications
- Train machine learning models
- Validate data pipelines
- Perform analytics
But on the other hand, finance, healthcare and other sensitive information must stay private. Giving technology teams real customer data risks exposure.
This creates bottlenecks, delays, and poor data quality that slow organizations down.
What is Data Masking?
Data masking is the process of hiding or de-identifying sensitive information. It replaces real data like names, dates of birth, and credit card numbers with fake yet realistic looking data.
For example, it can change a real phone number like 555-867-5309 to a masked number like 494-826-7929. The format stays intact, but the actual data is hidden.
This allows sharing of broader datasets safely across all teams that need sample customer data. Technology groups get realistically formatted information masking preserves usability for systems testing and analytics. Protection against breaches or misuse also strengthens since no actual private details are exposed.
Core Benefits of Data Masking
Data masking solves many pain points for organizations through various benefits:
First, it enables efficient system testing. Technology teams can access full datasets with realistic but scrubbed fake data. This lets them comprehensively test new platforms and migrate legacy systems without actual private data being exposed, removing privacy risks.
Broader access to properly masked data accelerates development of analytics models, AI training programs, and other business insights without fears of compliance violations. Masking facilitates productive collaboration as well, allowing sales, services, finance, technology and more groups to freely share integrated masked data through collaboration tools. This allows all teams to work together more effectively.
Masking also speeds up outsourcing initiatives. Partners can leverage large-scale masked datasets for offshore development, quality assurance testing and other outsourcing needs without seeing real private information.
Masked datasets enhance cybersecurity protections from both external breaches as well as insider risks like unauthorized snooping or harvesting of sensitive data during analysis since real details remain hidden.
Data masking facilitates more efficient usage and exchange of information across the business.
Masking Strategies
There are various masking approaches that can effectively hide sensitive data:
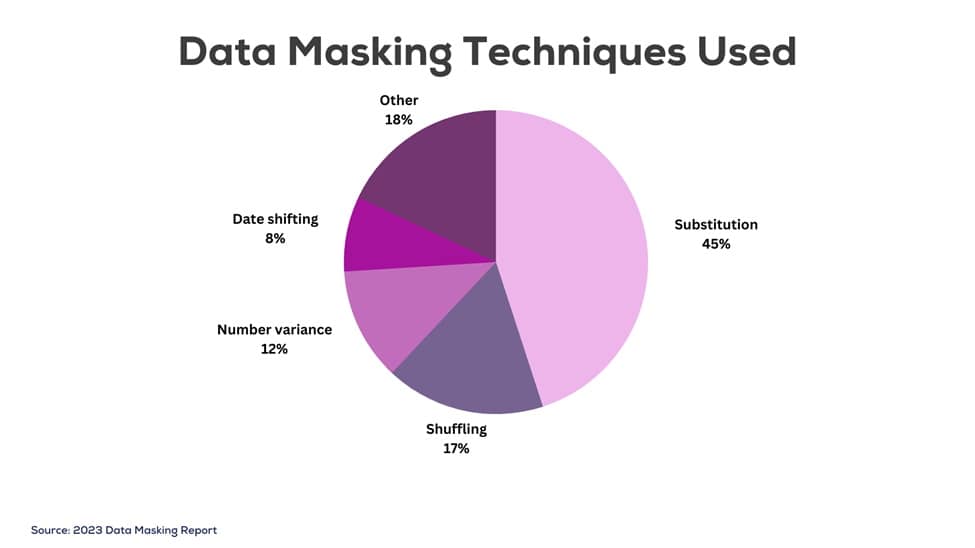
Substitution involves replacing sensitive data with fake but realistic substitute values. This includes changing people’s names, varying ages within a close range, or swapping in fake card numbers. The overall formatting stays intact while the actual data hides.
Shuffling scrambles parts of data, like swapping first and last names or shuffling the order of birthdate fields. This maintains referential integrity in datasets while hiding individual details.
Number variance alters sensitive numbers within a small, close range. For example, you may adjust salaries up or down consistently by 5-10% to mask real figures. Overall statistical distribution stays intact.
Date shifting moves dates by a consistent interval into the past or future. This can mask exact purchase dates, birthdates, and more while keeping logical date relationships and ranges.
Replacement values swap sensitive data with abbreviations, special characters, or codes. For example, masking “Visa” for card types. You can also use XXX, asterisks, or hashes in place of text strings.
Specialized algorithms dynamically mask each data type appropriately for usability without exposing real underlying info.
Masking in Action (Example)
Let’s walk through a data masking example:
Raw Patient Data:
- Name: Jane Smith
- DOB: 7/12/1982
- SSN: 123-45-6789
- Address: 123 Oak Rd
- Phone: 555-867-5309
- Email: jsmith@email.com
- Health Plan: Blue Cross PPO
Masked Patient Data:
- Name: Jennifer Johnson
- DOB: 2/03/1982
- SSN: 987-65-4321
- Address: 456 Elm Dr.
- Phone: 494-726-4839
- Email: jjohnson@email.com
- Health Plan: Green Shield HMO
All data remains logically coherent for testing systems. But with no actual patient details exposed.
Advanced algorithms dynamically mask various data types for customized protection.
Masking Techniques
Masking approaches include:
- Fully Automated – Auto-generate using software rules and manipulation algorithms without manual review. The fastest option for large datasets.
- Configured Automated – Configure masking software for custom requirements per data fields. For example, preserve location data but mask names. More controlled than fully automated.
- Assisted – Software suggests masking changes, but people review and modify to maintain data integrity as needed. Augments automation with the human eye.
- Manual – People manually mask data entirely by typing replacements or using encryption tools. Feasible for small datasets but not scalable.
Balancing automation with configurability tailors masking to specific data needs.
Implementing Masking Securely
To ensure masking is applied safely:
- Archive Original Data – The original source data should be backed up in a protected location. This preserves the ability to re-link masked records back if ever needed for audits.
- Mask Inside Trust Zone – Perform masking within the secure source data environment before transferring external. Avoid pipes that move raw data outside.
- Mask In-Place – Avoid making copies. Mask source datasets directly in their repositories. Copies multiply compliance risks.
- Use 256-bit Keys – Encrypt masking patterns using industry-standard algorithms and key lengths. Future-proof encryption strength.
- Control Data Access – Grant masked data access at the minimum level required for a specific purpose only on a timed basis.
- Mask Data in Transit – Encrypt any transfers of masking specs or masked data files through secured protocols like SFTP or HTTPS/SSL.
With diligent protocols, data masking adds protection rather than creating incremental risk.
Meeting Evolving Regulations
Data masking helps address rapidly evolving privacy regulations like:
- GDPR – Masking techniques like pseudonymization satisfy GDPR mandates to protect EU customer data and enable frictionless transfers across borders.
- CCPA/CPRA – Masking can be used by businesses to de-identify personal information of California residents to avoid at CCPA/CPRA obligations. However, businesses remain accountable for protecting privacy.
- HIPAA – Healthcare groups use masking to share PHI for uses like quality improvement and evaluation without written authorizations as mandated by HIPAA.
- PCI DSS – Masking cardholder details like Primary Account Numbers allows retailers to comply with PCI DSS data protection rules for payment systems.
- SOX – Masking improves controls over sensitive financial data to meet Sarbanes-Oxley internal controls requirements for financial reporting.
As regulations expand, masking allows more data usage without compliance risks.
Scalable Cloud-Based Masking
Traditional in-house masking posed challenges:
- Slow performance masking large volumes on-premises
- Limited scalability for growing datasets
- Minimal ability to mask data already in cloud platforms
- Complex to mask data across fragmented on prem and cloud stores
- Difficult to mask streaming real-time data in motion
Modern cloud-based data masking overcomes these gaps with:
Distributed Processing
Masking runs on the platform where data resides using scalable grid processing, not just locally. Dramatically faster performance masking data volumes from gigabytes to petabytes.
Broad Ecosystem Support
Connectors allow masking data sitting within databases, data warehouses, data lakes, and storage services across cloud and on-prem. Location agnostic.
Real-Time Masking
Instantly mask in streaming pipelines and message queues to prevent raw data exposure.
Centralized Control
Mask dispersed data silos consistently via unified policies controlled from a single pane of glass.
For today’s complex hybrid environments, only cloud data masking provides the versatility and speed demanded.
Future Opportunities With Synthetic Data
Emerging machine learning algorithms now allow generating fully artificial masked “synthetic” data modeled after patterns in real data:
- Train ML models faster using vast synthetically generated data unlabeled training sets. This overcomes small real-world labeled data samples holding back model accuracy.
- Share fully artificial data externally without any confidentiality risks. Expand ecosystems through essentially controllable data.
- Preserve statistical distributions and relationships between fields but introduce required randomness to prevent reverse engineering insights about real people.
- Use as benchmark data to more accurately assess model performance due to complete data control.
Synthetic data unlocks new frontiers in privacy protection, AI ethics, and model development.
Key Takeaways
In summary, data masking powers:
- Faster application development through expanded data access
- Improved analytics and AI with broader yet controlled datasets
- Secure collaboration via masked data sharing
- Reduced risk from unauthorized insider exposure
- Ongoing compliance as regulations evolve
Data masking reconciles critical data usage with privacy across expanding data sources. Organizations can confidently maximize data’s value while minimizing risks. Masking provides the foundation for data-driven innovation and trusted data exchanges.
FAQs
Does masked data always fully anonymize information?
It depends. Methods like substitution retain usability while de-identifying. More advanced techniques like differential privacy introduce mathematical noise to prevent re-identification even from masked data.
Can masked data be linked back to real identities?
In theory, it may be possible to re-identify some individuals through cross-analysis. Proper controls and advanced techniques limit this risk. However, masking alone does not guarantee full anonymization.
Is synthetic data generated by AI 100% privacy safe?
Since synthesis models are trained on real data patterns, there is a small risk of encoded biases leading to potential re-identification in some cases. Continued advances aim to mitigate this but some minimal risk likely remains. Proper controls remain crucial.
Can data masking ensure GDPR compliance alone?
Not necessarily. Masking supports GDPR but organizations remain accountable for comprehensive regulatory compliance across people, processes and technology. Masking contributes as part of a larger compliance program.
Final Thoughts
With powerful data masking capabilities now available, organizations can tap into information’s full potential while respecting privacy. Data masking delivers efficiency, intelligence, and trust.

{kind=link}